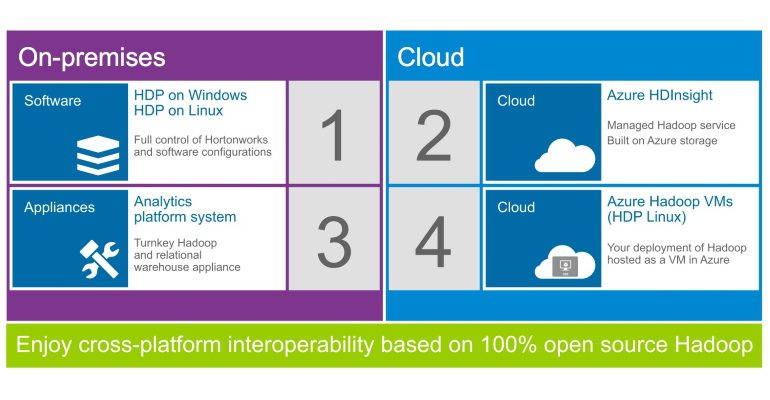
Under sina tio år har Hadoop gått från ett mindre projekt till ledande lösning för bearbetning av stora datamängder inom alla områden. Mycket har hänt under åren, och mer är på gång.
Efter flera år av planering och tankar kring hur extremt stora data mängder skulle kunna hanteras på ett effektivare sätt sjösatte Doug Cutting, som vid denna tid arbetade på Yahoo, 2006 sin projektidé Hadoop. Projektet startades under Apache-stiftelsen, och namnet och logotypen tog Cutting från sonens leksakselefant. Under åren som gått fram till idag, tio år senare, har oerhört mycket hänt och Hadoop har med sitt öppna ramverk helt förändrat marknaden för analysverktyg.
Under dessa år har det hållits ett flertal Hadoop Summit Event. Dessa hålls runt om i världen för att knyta samman tekniker och utvecklare samt för att väcka intresse för Hadoop. Datormagazin var på plats när Europas fjärde summit hölls i Dublin på Irland tidigare i år.
Detta blir dock inte någon vanlig rapportering från ett event. Istället visar vi på bredden hos Hadoop. För numera är det inte enbart ett sätt att bearbeta stora datamängder, utan Hadoop erbjuder mer eller mindre komplett hantering av data. Detta oavsett om det handlar om ostrukturerade data, flöden från sociala medier, satellitbilder, GPS-signaler, serverloggar, data som strömmas i realtid eller mer statiska data.
Öppet ramverk
Hadoop är ett ramverk, eller en verktygslåda, för programmerare. Det består i skrivande stund av över 30 olika underprojekt eller delprogram. En del av dessa kan köras som fristående moduler, medan andra fungerar som underliggande komponenter för att överliggande program eller själva ramverket ska få önskade funktioner.
Grunden och den gemensamma nämnaren för dem alla är dock att de hjälper oss att analysera eller behandla mer eller mindre obegränsade mängder data. Dock med en stor skillnad jämfört med traditionella och alternativa lösningar. Den öppna standarden innebär nämligen att mer eller mindre vem som helst kan utveckla och anpassa Hadoops olika projekt eller ta fram egna. Det är på detta sätt som Hadoop växer och hela tiden utvecklas. De som sedan utvecklar en Hadoop-baserad applikation behöver inte fokusera särskilt mycket på den grundläggande samordningen av arbetet, då detta sköts av ramverket. Lite på samma sätt som med ett API.
Hanteringen av data rymmer tre steg: Insamlingen, lagringen och bearbetning en. För Hadoop är det oväsentligt om dessa tre steg sker i en löpande process eller i separata steg. Ramverket omfattar nämligen lösningar för att hantera både statiska och strömmande data.
Du kan använda Hadoop till att söka igenom data efter ett visst mönster eller för att sammanställa statistik från olika sorters trafikloggar. Eller också kan du använda Hadoop för att behandla binärdata som vid omkodning av bilder och ansiktsigenkänning.
Det sistnämnda används bland annat av flera polismyndigheter i USA. Strömmad video från övervakningskameror analyseras för ansiktsigenkänning. Då Hadoop har en skalbar struktur kan samma system användas för såväl stora som små enheter.
Snabb hantering
En av de stora fördelarna med Hadoop är dess prestanda, vilken uppnås på flera sätt. Hadoop har under hela sin tid vunnit fördelar genom att bryta ner data i mindre delar och sedan bearbeta dessa parallellt. Det kan liknas vid att tjänsten delar upp indata, för att sedan samordna beräkningarna av samtliga delar samtidigt som det sker en löpande övervakning så att du får ut önskat resultat från dessa.
En annan del, eller rättare sagt ett sidoprojekt, som optimerar prestandan är Spark. Detta är en beräkningsmotor vilken erbjuder en enkel men uttrycksfull programmeringsmodell. Den arbetar primärt med maskinlärning. Dock arbetar den även med strömmande data och med att visualisera data. Då denna process sker fullt ut i minnet blir bearbetningen extremt snabb, när väl data är inlästa. För att optimera inläsningen till minnet, och även tillbaka till disk, bör Hadoop Distributed File System (HDFS) användas.
Som de flesta förstår går det inte att köra obegränsat stora datamängder i minnet på en server, oavsett hur kraftfull denna är. Därför är Spark konstruerat för att kunna skalas efter behov, data kan samtidigt bearbetas på multipla servrar.
Då filsystemet HDFS är distribuerat kommer filerna att spridas ut över flera noder i klustret, vilket även omfattar nätverket, och kan därför även nås överallt. De bör dock av prestandaskäl hållas lokalt på samma server eller serverpool för bästa prestanda. Bäst resultat uppnås med relativt stora filer som bearbetas med långa, sekventiella läsningar och skrivningar.
Själva resursfördelningen, eller lastbalanseringen, sköts dock inte av Spark utan av nästa modul kallad Yarn. Sistnämnda kan liknas vid ett operativsystem. Även Yarn är i sig ett eget ramverk för att fördela olika jobb mellan resurser och kluster.
Yarn består av flera delar. En av dem är Mapreduce, som är motorn för att hantera just parallell bearbetning av data. En annan del är Tez, som kan ses lite som ett mellanlager till Yarn för att optimera resurshanteringen.
Tez är optimerad för att hantera batch-körningar av olika slag. På grund av sin flexibilitet kan denna lösning många gånger radikalt reducera antalet jobb för en process, jämfört med tidigare lösning ar. Den är i flera sammanhang även effektivare än Mapreduce. Även Tez jobbar direkt i minnet, vilket ger en omedelbar respons på frågor.
Säkerhet och rättigheter
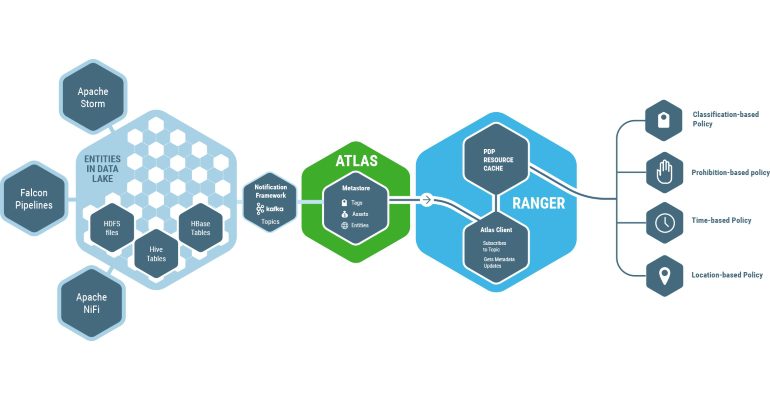
Något som är minst lika viktigt som prestanda är säkerheten. När det gäller Hadoop löses den sistnämnda primärt med hjälp av två funktioner kallade Atlas och Ranger (tidigare Argus). Det förstnämnda är enkelt uttryckt användargränssnittet mot alla metadata. Det hjälper till att klassificera alla data av både intern och extern karaktär. Det är här som alla data taggas (konton, personer, grupper etcetera) och allt sker centralt. Detta innebär att du bara behöver definiera åtkomstkontrollen en gång, sedan kan du applicera det på alla data.
Ranger ligger sedan som ett paraply över alla underliggande komponenter. Denna lösning hanterar tillgången till alla komponenter och tjänster med mera, baserat på användare och grupper. Du kan även styra synligheten för objekt och tjänster.
Båda funktionerna har funnits som separata moduler. Då de integrerats kan företag nu specificera policyer för att styra och kontrollera rättigheter samt säkerhet i realtid, detta över alla Hadoops komponenter. Det omfattar allt från vanlig accesskontroll till tids-, datum- och platsspecificerad accesskontroll. Dessutom får utvecklare nu en möjlighet att kombinera olika typer av skydd och rättigheter, så att exempelvis användare X har åtkomst till vissa objekt och data, men när han sedan befinner sig på icke godkända platser kommer dessa objekt inte att kunna nås.
Skyddet inbegriper även Knox. Detta är en tjänst som styrs av Ranger och som fungerar på ungefär samma sätt som en brandvägg. Knox definierar vem som får använda vad och när detta får ske.
Som komplement till dessa lanserades under Hadoop Summit även nyheten Apache Metron. Kortfattat är detta en avancerad säkerhetsanalytisk plattform för att upptäcka och reducera säkerhetsrisker i realtid. När en organisation angrips kan Metrons användare behandla och jämföra data från omfattande flöden över multipla plattformar i realtid, och stoppa den skadliga koden. Och denna behöver inte vara känd sedan tidigare, utan kan blockeras baserat på icke igenkända mönster.
Andra delar
Som nämndes tidigare består Hadoop av många komponenter. Några har belysts men ett par ytterligare förtjänar korta om nämnanden.
En sådan är Hue, ett webbgränssnitt för att administrera Hadoop. Detta gränssnitt kan användas tillsammans med Zookeeper för att bland annat samordna konfigurationsinställningar och aktivera respektive inaktivera tjänster över ett helt Hadoop-kluster.
Likaså bör Avro nämnas, ett system för att serialisera data. Den blir på så sätt enkel att tolka för andra system.
Sist har du Mahout, en programmeringsmiljö. Denna används för att ta fram maskinlärande applikationer.
Skalbart ger ekonomi
En annan anledning till den snabba ut vecklingen och acceptansen är det ekonomiska perspektivet. När det gäller Hadoop behövs inte superdatorer eller annan dyr, specialiserad maskinvara för att behandla stora datamängder. Du får skalbarhet och distribuerad databehandling på vanliga servrar. Detta ger möjlighet att bearbeta flera petabyte med en betydligt mindre budget. Dessutom är Hadoop utformat för att vara skalbart från en enda server till tusentals datorer i olika former av kluster.
Genom den öppna källkoden och de fria modulerna kan företag dessutom enkelt flytta data och lösningar till olika under liggande plattformar. Men värt att poängtera är att öppen källkod inte är detsamma som kostnadsfritt. Det behövs alltid servrar och sammanhållande lösningar och tjänster. Fast väljer du någon av alla molnbaserade tjänster kan du skapa ett kluster på några minuter med minimala startkostnader.